Le duplicate content peut être causé par de nombreux facteurs, notamment une mauvaise configuration de votre site ou de votre serveur web. Si le contenu dupliqué n’est pas toujours intentionnel, il n’empêche que vous devez être en mesure de l’identifier pour rectifier le tir.
En effet, les moteurs de recherche et particulièrement Google n’apprécient pas le duplicate content, et vous en ressentirez les conséquences dans votre ranking.
Avant de voir ensemble quelques astuces pour identifier le contenu qui a été dupliqué, vous devez connaître ce qui n’est pas considéré comme tel.
Qu’est-ce qui n’est pas considéré comme du duplicate content ?
Le contenu traduit
Si vous proposez le contenu de votre site dans différentes langues, Google ne le considère pas comme étant dupliqué. Quoique…
Vous devez faire attention à la qualité de votre traduction. Si le moteur de recherche se rend compte que le contenu est mal traduit, que le sens des phrases n’est pas naturel ou qu’il manque de « personnalité » alors il pourrait penser qu’il s’agit de duplicate content.
Vous devez donc être prudent, surtout si vous utilisez des logiciels de traduction.

Le meilleur moyen pour éviter de genre de problème est de faire appel à un traducteur professionnel, un humain donc. Votre contenu ne sera pas considéré comme dupliqué et vous pourrez par la même occasion proposer un texte de meilleure qualité à votre cible internationale.
Le contenu des sites mobiles
Si votre site n’est pas responsive vous avez sans doute créé une version mobile. Dans ce genre de situation, il est fort probable que l’url de votre site desktop soit différente de celle sur mobile.
Normalement, lorsque Google voit deux urls différentes (même si elles appartiennent au même site) avec un même contenu alors il le considère dupliqué.
Mais comme pour tout, il y a une exception à la règle. Sur mobile vous ne risquez pas de faire du duplicate content, notamment parce que Google n’a pas les mêmes robots d’indexation sur ce support.




Comment identifier le duplicate content ?
Maintenant que vous savez ce qui n’est pas considéré comme du duplicate content, voyons ensemble quelques astuces pour mieux identifier le contenu qui l’est.
1. Effectuez une recherche Google
Cette première méthode est la plus simple et c’est par là que vous devez commencer.
L’objectif va être d’identifier si des mots-clés ou expressions-clés sont réutilisées sur plusieurs pages de votre site. Pour cela, saisissez la recherche suivante :

Google va vous afficher toutes les pages de votre site qui contient exactement le même terme saisit après « Intitle ».
Pour être efficace dans votre recherche de duplicate content n’hésitez pas à être spécifique.
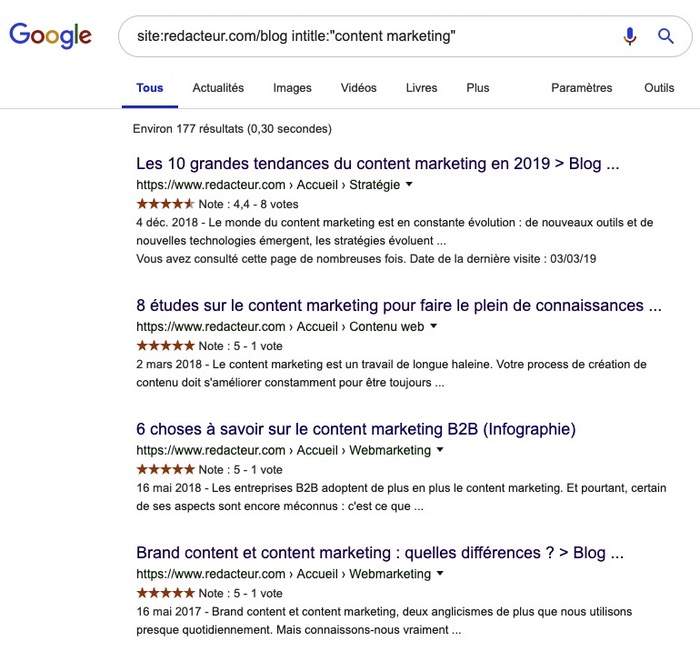
Cette méthode peut également être utilisée pour trouver du contenu dupliqué à travers le web en général, et pas seulement sur votre site. Dans ce cas vous devez simplement saisir : Intitle:’mot-clé’.
2. Utilisez un outil spécifique
Il existe plusieurs outils spécialement dédiés à la recherche de duplicate content. On peut citer :
Siteliner est très facile et rapide d’utilisation. Il vous suffit d’indiquer l’url de votre site et l’outil s’occupe de scanner vos différentes pages et d’identifier le pourcentage de contenu dupliqué.
Vous pouvez même accéder à un rapport plus détaillé. En cliquant sur les différentes urls vous verrez le texte dupliqué.
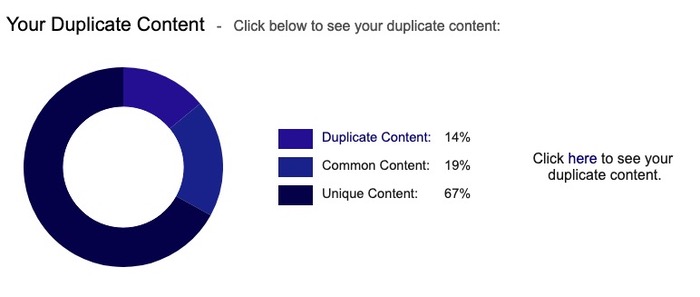
Ne vous arrêtez pas au pourcentage affiché. Prenez le temps de regarder vos différentes pages car l’outil peut considérer le texte de votre header comme du duplicate content. En réalité c’est le texte de votre page en elle-même qu’il faut analyser.
Pour pousser vos vérifications plus loin, je vous conseille d’utiliser Copyscape.
Si par exemple vous avez repéré du contenu dupliqué sur Siteliner, il vous suffit d’indiquer l’url de la page en question dans Copyscape et l’outil vous affiche toutes les pages web sur lesquelles il a trouvé des similarités.
Sur Redacteur.com tous les textes de nos rédacteurs sont analysés par CopyScape. Vous avez ainsi la garantie de recevoir un texte unique, quelle que soit votre demande.





La Google Search Console, un outil qui n’est plus d’actualité
Il était encore possible jusqu’à fin février 2019 de rechercher le contenu dupliqué via la Google Search Console.
Il vous suffisait de vous rendre dans « Amélioration HTML » ou encore dans « Erreurs d’exploration » mais ce service n’est maintenant plus proposé par Google.
Vous pouvez donc procéder comme vu dans les deux point précédents.
Si vous souhaitez obtenir des textes uniques ou ré-écrire un contenu qui semble avoir été dupliqué, n’hésitez pas à vous rendre sur Redacteur.com. Vous serez mis en relation avec des rédacteurs professionnels.
À lire aussi : 5 choses à faire pour résoudre les problèmes de duplicate content