Googlebot, le Robot d’indexation de Google est un robot numérique parcourant en permanence les pages des sites internet. Lorsqu’il découvre une nouvelle page, il en analyse le contenu, et détecte les liens (internes et externes) qu’il y rencontre.
Il va suivre ses liens de page en page et stoppera son analyse lorsqu’il rencontrera une page d’erreur, ou ne contenant aucun lien. Googlebot visite, collecte et indexe les pages, et contrôle aussi le degré de vulnérabilité des pages en question.
Le robot de Google est enfin en mesure de vous donner des informations à propos des textes et sur le référencement naturel de votre site web. Son travail se décompose en 2 étapes.
Le crawl
Googlebot va commencer par visiter un site web, explorant son contenu, puis en suivant les différents liens qu’il y rencontrera. Il collecte cet ensemble de données et en retire le plus d’informations possible.
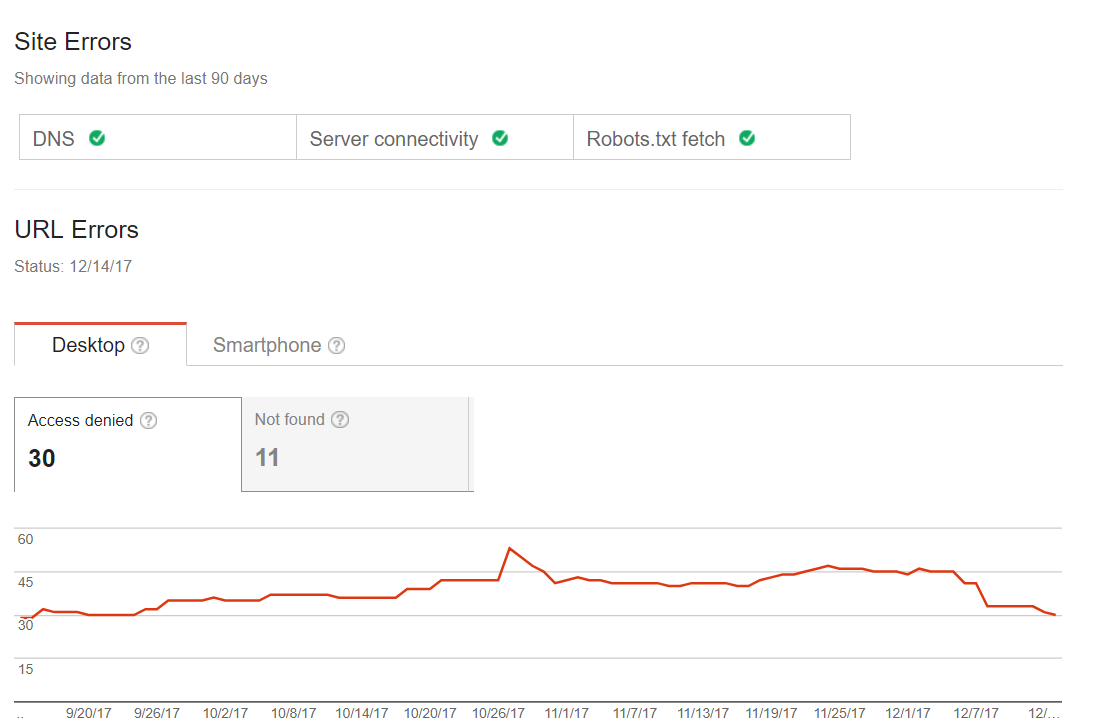
Évidemment, le robot de Google a une nette préférence pour les contenus originaux, et les sites web régulièrement alimentés en contenu récent sont la garantie de voir le crawler plus fréquemment.
En clair, plus votre site est alimenté en contenu, plus vos articles seront indexés rapidement : c’est un système basé sur le renouvellement continu des données.
À lire aussi : SEO : 9 outils pour analyser le positionnement de son site sur Google




L’indexation
L’ensemble des éléments ainsi collectés seront ajoutés à l’index de Google, qui depuis 2010 et le lancement de « caféine » arrive à enregistrer les nouvelles informations en très peu de temps.
Si Google stoppe son nombre de résultats à 25 270 000 000 (pour une recherche de type « e », ou « the » par exemple), le nombre de pages indexées dépasse de loin ce chiffre dont on estime qu’il serait de centaines de milliers de milliards.
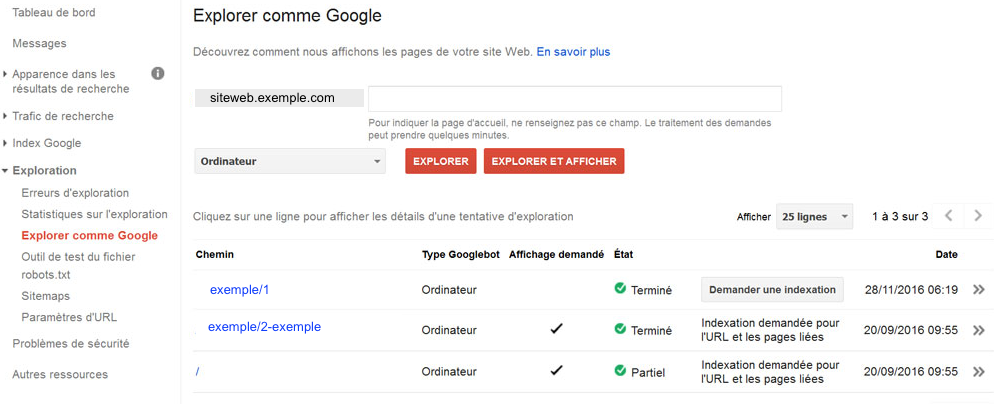
L’indexation donc, lors de laquelle Google fait une étude et organise les données récoltées par Googlebot lors de son crawl, dans des centres d’informations. Le moteur de recherche va ensuite effectuer le classement de ces données au sein de son index principal.
Vous le savez, être indexé dans le moteur de recherche est très important. Faciliter le travail de GoogleBot est donc une bonne idée. Voici quelques erreurs fréquemment commises sur l’indexation de vos contenus.
À lire aussi : Content marketing : comment réussir un article de type « liste » ?
Forcer l’indexation
Si vous avez une nouvelle page stratégique et importante à indexer le plus rapidement possible, vous pouvez indiquer son URL à Google. Il vous suffit d’aller dans votre espace Google Search Console et d’inspecter l’URL en question.
Attention toutefois à ne pas inspecter trop d’URL pour l’indexation : vous disposez d’un quota au-delà duquel vous ne pourrez plus vous servir de cette astuce. Si vous souhaitez accélérer l’indexation de plusieurs URLs, lisez ce qui suit !
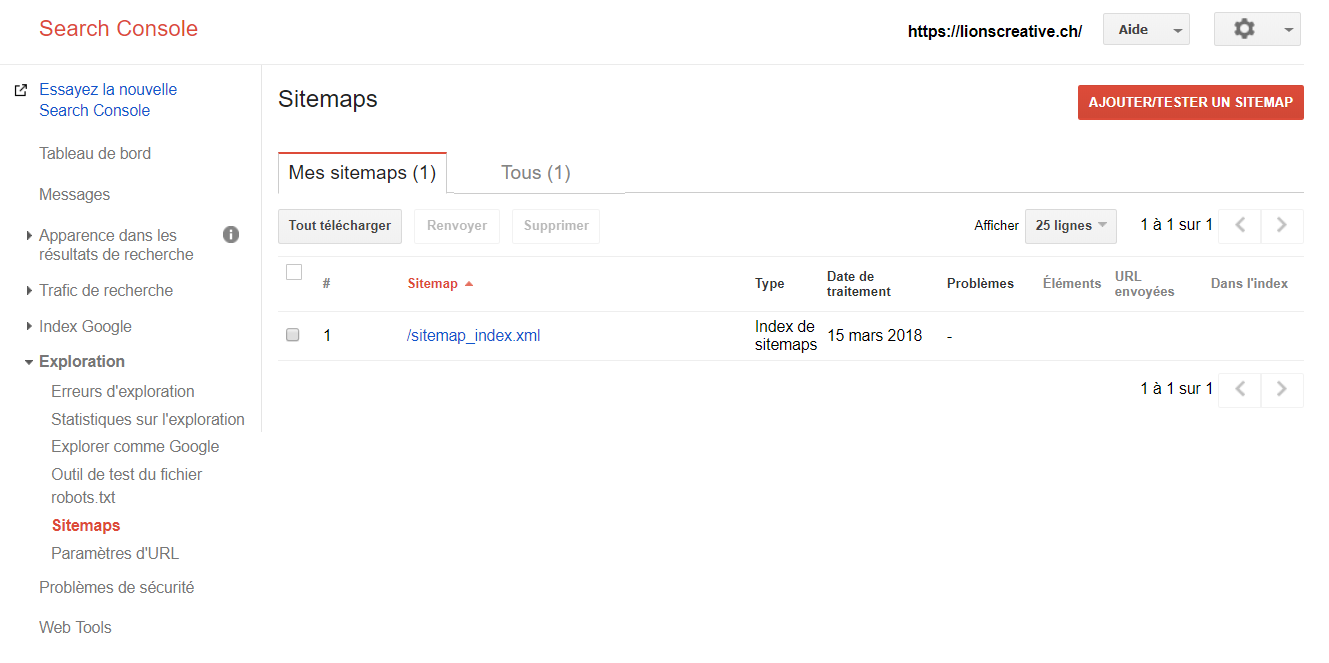
Soumettre son sitemap
Votre site dispose d’un sitemap, n’est-ce pas ? C’est un fichier très utile qui guide les robots crawler à travers votre site. Au lieu d’attendre sagement que le Googlebot passe par là, vous pouvez adopter une démarche active, en soumettant votre sitemap, toujours grâce à la Google Search Console.

Cela ne doit pas vous dispenser d’ajouter une directive de sitemap au sein de votre fichier robots.txt aide les autres crawlers qui n’offrent pas tous d’option de soumission. En parlant du robots.txt…
Le fichier robots.txt
Avant toute autre chose, le robot d’un moteur de recherche va vérifier votre fichier robots.txt. Ce fichier indique aux robots des directives sur quels chemins d’URLs ils ont l’autorisation d’emprunter.
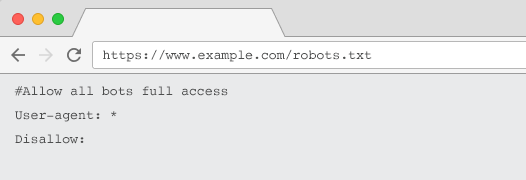
Ces directives ne sont pas toujours respectées : bien sûr, les crawlers de la plupart des moteurs de recherche vont obéir à ces instructions. Les crawlers hostiles, spambots, robots qui scannent les vulnérabilités ou encore des scrapers d’email n’en ont cure.
Vous pouvez valider votre fichier robots.txt dans le testeur robots.txt de de la Google Search Console. Sans ces directives, Googlebot agira « par défaut » : il va donc crawler et indexer tout ce qu’il trouvera, et vous gaspillerez votre précieux budget de crawl.
Optimiser le budget de crawl
Le robot de Google dispose d’un quota d’un certain nombre de pages à crawler sur votre site. Cela s’appelle le « budget de crawl ». Vous pouvez le faire dans le fichier robots.txt qui insérera les balises « Meta » correspondantes sur ces pages.
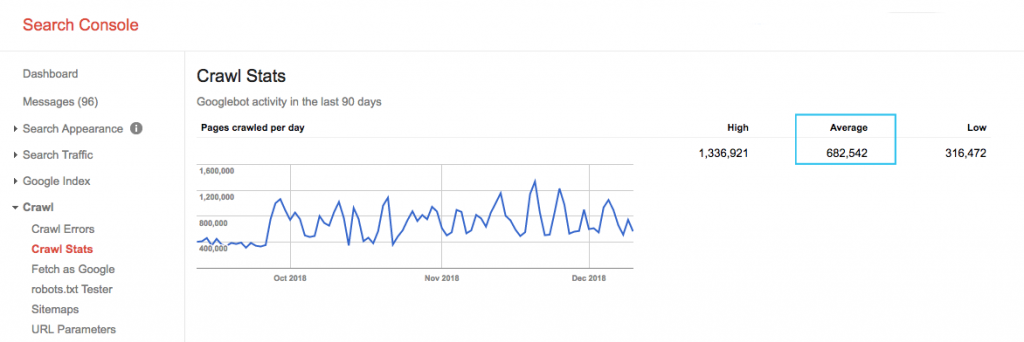
Vous devez donc montrer à GoogleBot les pages à parcourir, mais aussi celles qu’il ne doit pas parcourir, comme :
- les landing pages,
- les résultats de recherche,
- les pages de remerciement
Les paramètres d’URL (comme les balises UTM) peuvent également être problématiques et générer du contenu dupliqué, tout en gaspillant du budget de crawl.
Veillez à bien Ajouter un attribut de lien rel=canonical aux pages contenant des paramètres et assurez-vous que ceux-ci sont bien configurés dans votre Google Search Console.
Toute instruction utilisable dans une balise « Meta robots » grâce à votre robots.txt peut également être injectée côté serveur, comme élément de réponse dans l’en-tête HTTP avec la balise « X-Robots-Tag ».
À lire aussi : Pillar Page & Topic Cluster : comment les utiliser pour votre SEO ?
Vous voilà prêts à vérifier et optimiser la gestion de vos robots, en vous assurant qu’ils indexent votre contenu le plus efficacement possible !